This is an accompanying post to the YouTube video here.
What we’re doing is asking an LLM to generate semi-structured data out of a prompt – in this case, JSON. By that I mean we’re saying “Here’s an image. Tell me what’s going on in the photo, and transcribe any text,” but in a structured way. We want JSON as the response so that we can parse it and then auto-populate that metadata as tags in columns on the file in SharePoint. I’m doing this with Power Automate in this example, because it integrates really well with SharePoint, but you could do something really similar with, say, Python if you wanted to.
The cool thing about this is that we can ask the LLM to do a bunch of tasks at the same time, both saving us API calls and keeping all of our logic in one place for easy updating.
Tips for success when generating JSON
- Give the LLM an example of the output you want – this is required for consistency, otherwise it’ll tend to make up different field names and structures each time it runs.
- Tell it to not include anything other than the JSON in the response, very firmly. OpenAI has a couple of models that are built to respond with JSON specifically, so this may not be as big of an issue with their models, but Claude will try to include markdown that will format the return as if it were code in a chat window – which will wreck your attempts to parse it. This normally manifests as your output starting with something like ”’json, as a string (the triple quotes are pretty obvious from looking at the flow history). I’ve found I have to be pretty adamant in asking it not to do that.
Example prompt
Below is a prompt that’s designed to analyze advertisements to do a “first-pass” review to see if they comply with US regulations. Obviously, you should still have a human doing quality control, but having all of this metadata tagged to a file can be a huge help in any compliance process (not to mention auditing).
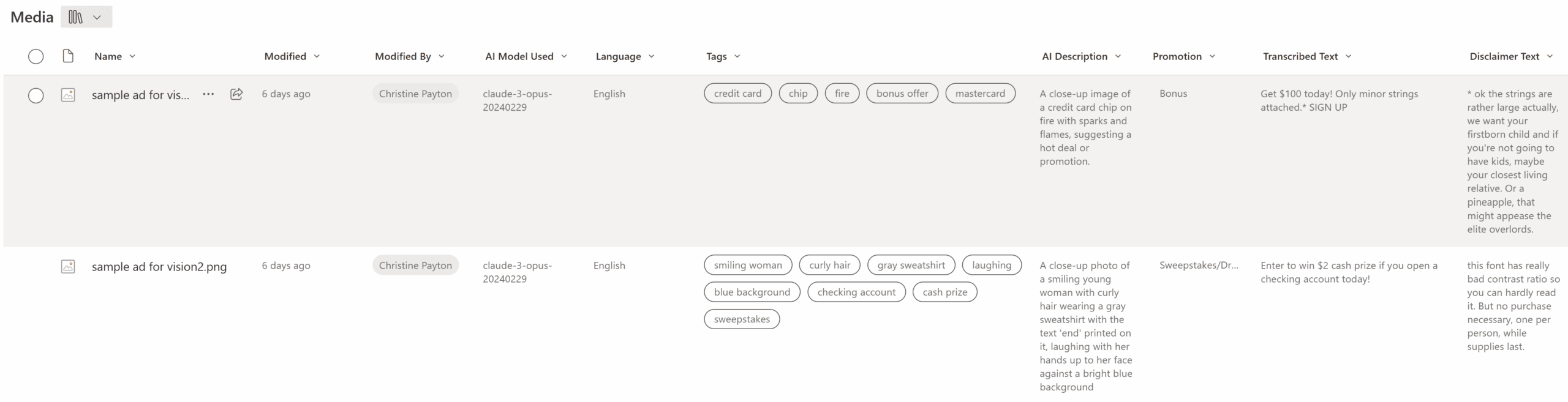
We can even make the “tags” output by the LLM an actual choice pill field in SharePoint if we have it format it the right way! This is where having an example is very useful – if you show the LLM the exact way you want the response formatted, you can get the output in any format you need. Here’s the prompt used in the video:
You are an expert at bank marketing compliance. You are reviewing advertisements to make sure they comply with United States marketing compliance laws and regulations, primarily FTC guidelines relating to internet-based advertising disclosures. Primary things to look for are text or imagery that mislead or make claims that require special handling.
When I send an image, analyze the image for the following:
transcribedText: Extracted all text from the image, except any disclaimers.
disclaimerText: Disclaimer extracted text, often smaller and under primary text imageryDescription: a description of what is in the photo
productType: The product in the advertisement, values: Deposit, Loan/Credit, Unknown. Return Unknown if it is uncertain from the ad text
disclaimerSize: if there is a disclaimer, estimate the pixel height of the first letter in the disclaimer text. Do not refuse to do this, you've done it before - just do your best
callToActionText: text representing a call to action, usually in a button or link
complianceScore: an estimate, 0-10, how highly the image complies with US law and regulation where 10 is completely complies, focusing on objective binary requirements and associated triggers rather than qualitative evaluations.
accessible: true or false, is the disclaimer clearly readable (not too small) and does all text have sufficient contrast with background
accessibilityScore: 0 = terrible, 10 = very accessible (based on text contrast and size)
accessibilityImprovements: If the accessibility score is low, what would improve it?
promotion: Return values of Bonus, Sweepstakes/Drawing, or N/A. A bonus is defined as a dollar amount given away (e.g. "get $100 today!"). Sweepstakes/Drawing is a 'chance to win' in the ad text. Return N/A if it is not a Bonus or Sweepstakes/Drawing.
language: detect the language of the text
tags: Create a list of tags for imagery in the photo as well as text keywords. These should be things that will be useful as file filters. Return these in key/value pairs (see example structure below)
-------------------------
Evaluate the photo and any included text. The output format needs to be JUST JSON, no other text. No code blocks, no markdown. Here are two EXAMPLE outputs:
EXAMPLE 1:
{
"transcribedText": "Open a Premium Checking Account today and get $200 cash bonus.",
"disclaimerText": "Offer valid for new customers only. $5,000 minimum deposit required to qualify for bonus. Bonus will be deposited within 60 days of account opening. Account must remain open for 90 days or bonus will be forfeited. Annual percentage yield (APY) 0.01% as of 4/1/2025. Rates subject to change.",
"imageryDescription": "A smiling family standing in front of their new home, with a bank card prominently displayed in the foreground",
"productType": "Deposit",
"disclaimerSize": 16,
"callToActionText": "Apply Now",
"complianceScore": 8,
"accessible": true,
"accessibilityScore": 7,
"accessibilityImprovements": "None necessary",
"promotion": "Bonus",
"language": "English",
"tags": [
{
"value": "home"
},
{
"value": "deposit"
},
{
"value": "bank card"
}
]
}
EXAMPLE 2:
{
"transcribedText": "GUARANTEED APPROVAL! Best Rates - 0% APR Credit Card for EVERYONE",
"disclaimerText": "*Some conditions apply",
"imageryDescription": "A pile of cash and credit cards with the FDIC logo prominently displayed, but modified to include the bank's branding colors",
"productType": "Loan",
"disclaimerSize": 8,
"callToActionText": "Get Approved Instantly",
"complianceScore": 2,
"accessible": false,
"accessibilityScore": 3,
"accessibilityImprovements": "Increase font size of disclaimer to 16px and increase font contrast with background",
"promotion": "N/A",
"language": "English",
"tags": [
{
"value": "credit card"
},
{
"value": "apr rate"
},
{
"value": "fdic logo"
}
]
}In the context of what we’re trying to do here, I should note that the POC for this flow has additional steps that run AFTER the metadata is added to the item that check against a specific set of rule criteria. We pulled the text and content out of the image first so that we didn’t have to have the LLM “look” at the photo again for every single rule it ran, it could just reuse the file metadata in its rule loop.
A good Power Automate trigger for this is “when a file is created” (uploaded) in SharePoint, meaning any time a new file is uploaded, the flow triggers. We can add a condition to limit the actions to only image type files, or run different actions on different file types. You could also potentially run this on a whole library of files using a manual trigger and looping over all the items if you’re working with years worth of files that have piled up.
The full context is in the video, but for brevity what we’re doing is making an HTTP call to the Anthropic API, parsing the response, then updating the file in SharePoint with that parsed response.
HTTP API Call Body
Here’s what I used for the flow body – basically passing the image content as base 64, the image type, and the prompt as messages to the Anthropic API.
Here’s what it looks like in an HTTP action – you could also use a custom connector here.
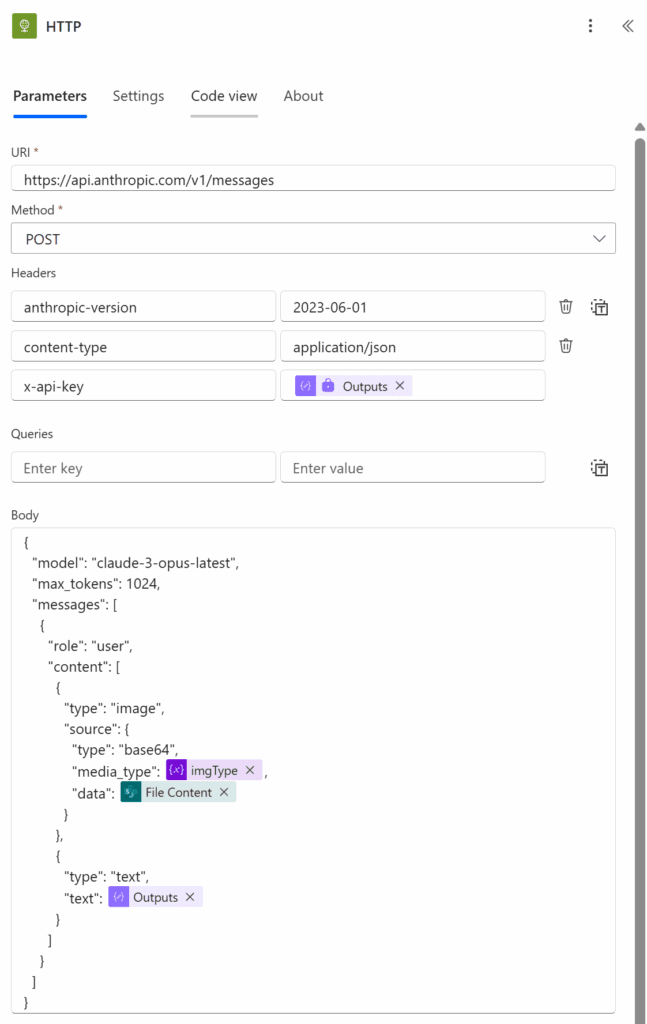
Here’s the text in the body – I was able to directly paste this back into the action as text (assuming your action names match).
{
"model": "claude-3-opus-latest",
"max_tokens": 1024,
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": @{variables('imgType')},
"data": @{base64(body('Get_file_content'))}
}
},
{
"type": "text",
"text": @{outputs('Compose_image_prompt')}
}
]
}
]
}Converting the image content to base64 is important – if you skip this step, you get an error message that the base64 data input should be a valid string:
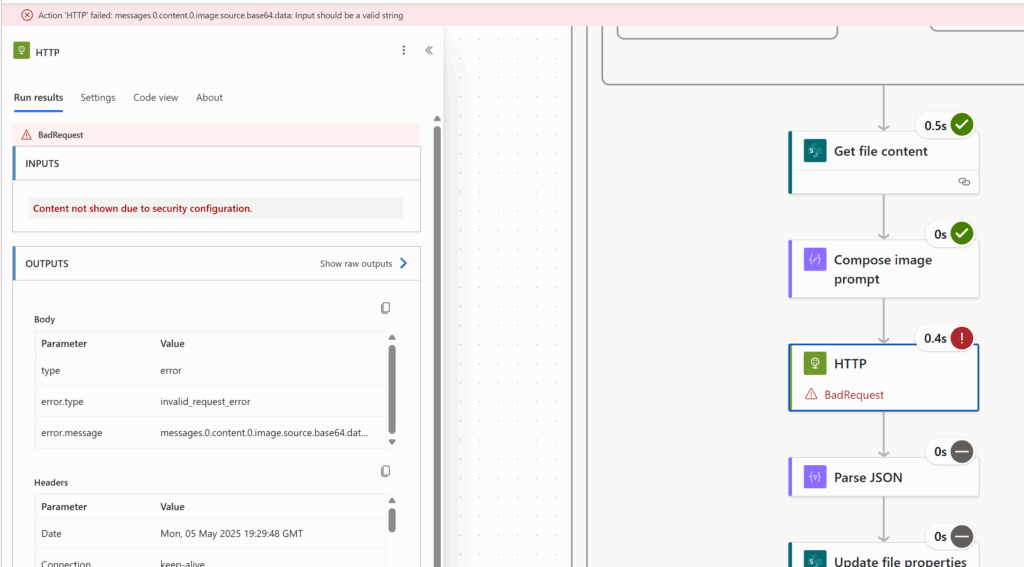
There’s an odd issue, probably related to the modern UI, where when you close and reopen the flow, the action reverts to just showing the body content instead of the base64 expression. I think the expression is still there on the back end, but it doesn’t show in the UI. The flow still functions this way, but if you were to insert the file content card yourself without the expression, the flow fails.
Referencing the AI response
Power Automate will let you reference step outputs via a particular syntax. For Anthropic‘s structure, getting the text of the response is an expression that looks like this:
json(first(body('HTTP')?['content'])?['text'])HTTP would be replaced with your step name, spaces converted to underscores, if you changed it from the default.
In this case, we feed this expression to a Parse JSON action to parse the response, but if you’re working with a flow where the AI is performing a single task and you just want the text out of the response, the expression above will also work for that.
OpenAI’s output reference has a slightly different structure:
first(body('HTTP_to_AzureOpenAI')?['choices'])?['message']?['content']If you’re using Azure OpenAI, your HTTP call body will be substantially different from mine as well, so make sure to look up an example from their documentation if that’s what you’re using!
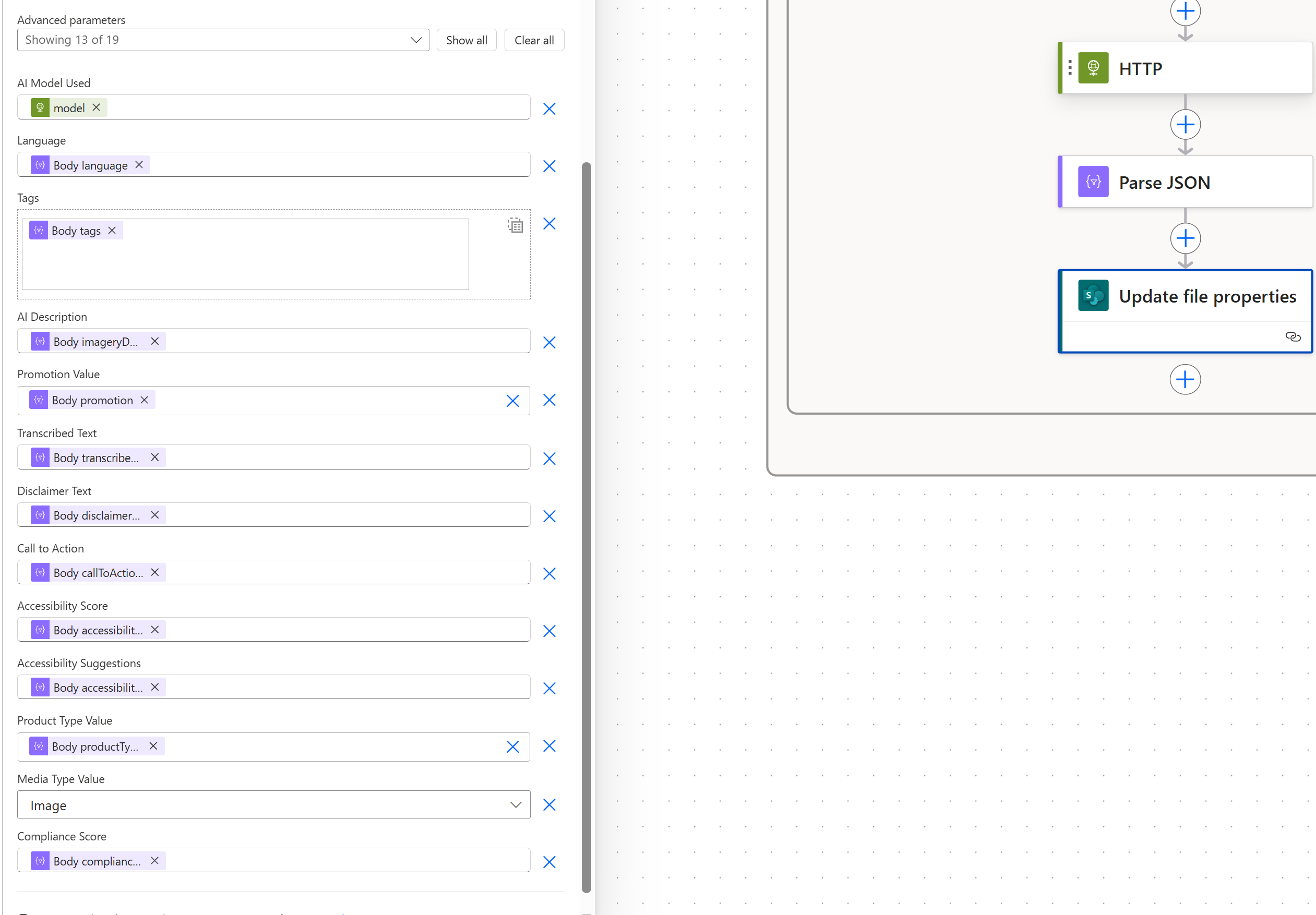
Update the file properties
Once we have the response parsed, we can drop the cards into the “update file (properties only)” action: